Retrieval-Augmented Generation (RAG)¶
Retrieval-Augmented Generation, commonly known as RAG, is an architectural pattern that enhances the capabilities of Large Language Models (LLMs) by connecting them to external, up-to-date knowledge sources. It combines a retrieval system with a generative model to produce more accurate, factual, and contextually relevant responses.
Why RAG?¶
Standard LLMs are trained on vast but static datasets. This leads to several limitations:
Knowledge Cutoff: The model’s knowledge is frozen at the time of its last training, making it unaware of recent events or information.
Hallucinations: LLMs can “hallucinate” or generate plausible but incorrect information when they don’t know the answer.
Lack of Transparency: It’s difficult to trace the source of the information an LLM provides, making it hard to verify its accuracy.
Generic Responses: Without specific context, responses can be too general and not tailored to a user’s specific domain or private documents.
RAG addresses these issues by grounding the LLM’s response in relevant, retrieved information.
How RAG Works¶
The RAG process can be broken down into two main stages: Retrieval and Generation.
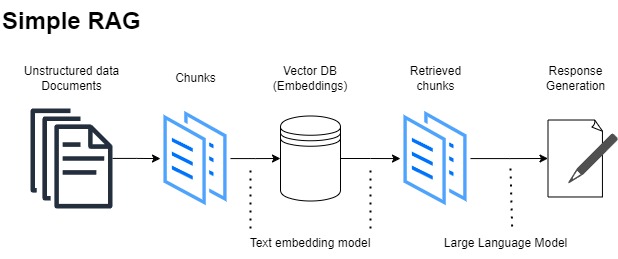
A simplified RAG workflow.¶
- Retrieval Stage
When a user submits a query, the RAG system doesn’t immediately send it to the LLM. Instead, the query is first sent to a retriever. The retriever’s job is to search a knowledge base (like a collection of documents, articles, or a database) and find the most relevant snippets of information related to the query. This is often done using vector search techniques.
- Generation Stage
The original query and the retrieved context are then combined into a new, augmented prompt. This enriched prompt is sent to the generator (the LLM). The LLM uses the provided context as its source of truth to synthesize a final, coherent answer.
Core Components¶
A typical RAG pipeline involves several key components:
Indexing¶
Data Loading: Loading your documents from various sources.
Chunking: Splitting large documents into smaller, manageable chunks.
Embedding: Using an embedding model to convert these chunks into numerical vectors.
Vector Store: Storing these vectors in a specialized database (a vector store) for efficient searching.
Retrieval¶
The retriever searches the vector store to find the document chunks whose embeddings are most similar to the user query’s embedding.
Generation¶
The LLM receives the query and the retrieved chunks. It is instructed to generate an answer based only on the provided context, which significantly reduces the chance of hallucination.
Benefits of RAG¶
Access to Current Information: RAG models can provide answers based on the latest information by simply updating their knowledge base, without needing to be retrained.
Reduced Hallucinations: By grounding the model in factual, retrieved documents, RAG significantly reduces the likelihood of generating incorrect information.
Improved Transparency: Since the model’s response is based on specific retrieved documents, the system can cite its sources, allowing users to verify the information.
Cost-Effective: Augmenting an LLM with a knowledge base is far more economical than fine-tuning or retraining the entire model for new knowledge.